
सुशील जोशी [Hindi PDF, 170kB]
वैसे तो पिछले सालों में जेनेटिक्स के विकास के दौरान इस बाबत मत बदलते रहे हैं कि जीन क्या चीज़ है, उसकी भूमिका क्या है, उसे कैसे परिभाषित करें। यहाँ मैं उस पचड़े में नहीं पड़ रहा हूँ। मैं तो आपको यह बताने जा रहा हूँ कि सामान्यत: जीन की जो भी भूमिका समझी जाती है, वह उसे कैसे निभाता है। शायद इतना कहना ही पर्याप्त होगा कि सामान्य तौर पर यह माना जाता है कि जीन डीएनए नामक विशाल अणु का एक छोटा-सा हिस्सा होता है जो प्रोटीन के निर्माण का संचालन करता है।। किसी भी जीव में उपस्थित डीएनए को उस जीव का जीनोम भी कहते हैं। डीएनए हरेक कोशिका में गुणसूत्रों के रूप में पाया जाता है (यह बात एकदम सही नहीं है क्योंकि केन्द्रक विहीन कोशिकाओं में डीएनए गुण-सूत्रों के रूप में नहीं पाया जाता) और सामान्य कोशिका विभाजन (माइटोसिस) के दौरान इनकी प्रतिलिपि बनकर दोनों कोशिकाओं को मिलती है। अर्धसूत्री विभाजन (मियोसिस) के समय दोनों कोशिकाओं को पूरा डीएनए नहीं मिलता।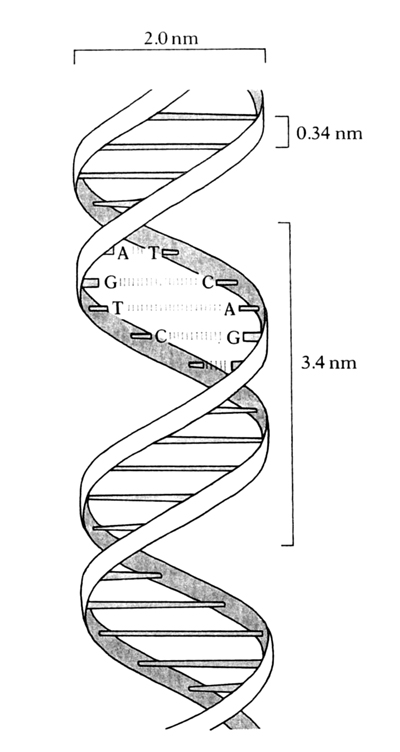 डीएनए की बनावट
डीएनए की बनावट
कई वर्षों के शोध। के बाद पता चल पाया था कि सजीवों में आनु-वांशिकता की इकाई न्यूक्लिक एसिड है - डीऑक्सीराइबोन्यूक्लिक एसिड यानी संक्षेप में डीएनए। डीएनए का अणु राइबोस शर्करा की एक ाृंखला से बना होता है। ये डीऑक्सीराइबोस इकाइयाँ आपस में फॉस्फेट समूहों के ज़रिए जुड़ी होती हैं। प्रत्येक डीऑक्सी-राइबोस शर्करा पर निम्नलिखित चार में से किसी एक क्षार का अणु जुड़ा होता है: एडीनीन, थायमीन, सायटो-सीन, गुआनीन। इस पूरी इकाई - एक डीऑक्सीराइबोस शर्करा, एक फॉस्फेट समूह और एक क्षार - को एक न्यूक्लियोटाइड कहते हैं। डीएनए अणु की संरचना में न्यूक्लियोटाइड की दो शृंखलाएँ एक-दूसरे के सम्मुख होती हैं। इस संरचना की विशेषता यह है कि इसमें यदि एक शृंखला पर एडीनीन है, तो उसके सामने वाली शृंखला पर थायमीन होगा, और यदि एक ाृंखला पर सायटोसीन है तो दूसरी पर गुआनीन होगा। इन चार क्षारों को A, T, C, G कहने की परिपाटी है। चित्र में डीएनए के एक हिस्से की संरचना बताई गई है।
आप देख ही सकते हैं कि यदि इस अणु की एक शृंखला ले ली जाए, तो दूसरी शृंखला आसानी से निर्मित की जा सकती है। होगा यह कि दूसरी शृंखला पर क्षार उपरोक्तानुसार सामने जमते जाएँगे। डीएनए द्वारा स्वयं की प्रतिलिपि बनाने की यह क्रिया आनुवंशिकी का आधार है। और इसे रेप्लिकेशन (प्रतिलिपिकरण) कहते हैं। डीएनए की दूसरी भूमिका प्रोटीन निर्माण की है। अब हम उसी पर चर्चा करेंगे।
प्रोटीन, जैसा कि आप जानते ही हैं, अमीनो अम्लों के बहुलक (पॉलीमर) हैं। कुल मिलाकर 20 अमीनो अम्लों को अलग-अलग क्रमों में और अलग-अलग संख्याओं में जोड़कर अलग-अलग प्रोटीन बनते हैं। मनुष्य के शरीर में कुछ लाख प्रोटीन बनाए जाते हैं। यह न समझिए कि सारे प्रोटीन हर समय हरेक कोशिका में बनाए जाते हैं। कोशिका-विशेष, समय- विशेष और पर्यावरण से निर्धारित होता है कि कौन-से प्रोटीन बनाए जाएँगे।। कहने का मतलब है कि मानव कोशिका इतने विभिन्न प्रोटीन बनाने की क्षमता रखती है।
इस सवाल ने कई दशकों तक जीव वैज्ञानिकों को उलझाए रखा था कि वह कौन-सा पदार्थ है जो कोशिका का नियंत्रण करता है और जीन के गुणधर्म (जैसे आँखों या बालों की रंगत) तय करता है।
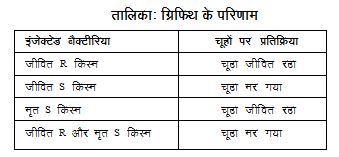
ग्रिफिथ का प्रयोग
1928 में फ्रेड ग्रिफिथ ने एक प्रयोग किया जिससे पता चला था कि नियंत्रण का काम डीएनए के ज़रिए होता है। ग्रिफिथ ने निमोनिया पैदा करने वाला बैक्टीरिया लिया। इस बैक्टीरिया की दो किस्में होती हैं - एक जो रोग पैदा करती है (S किस्म) और दूसरी जो रोग पैदा नहीं करती (R किस्म)। उन्होंने दर्शाया कि जीवित S किस्म से संक्रमित चूहे मर जाते हैं जबकि R किस्म से संक्रमित चूहे जीवित रहते हैं। उन्होंने यह भी देखा कि यदि च् किस्म को गर्मी से मार डाला जाए और फिर चूहों में इंजेक्ट किया जाए, तो वे चूहे नहीं मरते। यह अवलोकन तो समझ में आता है। मगर अगला अवलोकन थोड़ा चकराने वाला था। जब ऊष्मा से मारे गए च् किस्म के बैक्टीरिया का इंजेक्शन लगाते समय साथ में जीवित R किस्म के बैक्टीरिया भी मिला दिए जाएँ, तो चूहे मर जाते हैं। और तो और, चूहों के शरीर में बड़ी तादाद में जीवित S किस्म के बैक्टीरिया प्राप्त हुए। ये कहाँ से आए? इसी तरह के कई प्रयोगों के माध्यम से ग्रिफिथ को यकीन हो गया कि हो न हो, ऊष्मा से मारे जा चुके S किस्म के बैक्टीरिया ने अपना रोगकारी गुण R किस्म को हस्तान्तरित कर दिया है। उनका निष्कर्ष था, आनुवंशिक पदार्थ एक किस्म से दूसरी किस्म में चला गया है। अन्य शोधकर्ताओं के प्रयोगों से यह भी पता चला कि बैक्टीरिया की किस्म बदलने के लिए ज़रूरी नहीं कि चूहे में ही प्रयोग किया जाए। परखनली में भी यही क्रिया हो जाती है। इसके दो साल बाद पता चला कि ङ किस्म की कोशिकाओं को च् किस्म में तबदील करने के लिए R किस्म की पूरी कोशिका की ज़रूरत नहीं है। मात्र उसके सत से काम चल जाता है। यानी जो पदार्थ Rकिस्म को S किस्म में बदल रहा है वह गर्मी से भी अप्रभावित रहता है और सत बनाने की क्रिया से भी। अन्तत: एवरी, मैक्लियॉड व मेक्कार्टी ने काफी मशक्कत के बाद पता लगाया कि परिवर्तनकारी पदार्थ डीएनए है।
प्रोटीन निर्माण पर नियंत्रण
जब डीएनए की संरचना पता चली तो यह तुरन्त स्पष्ट हो गया था कि इसकी प्रतिलिपि बनाने की क्रिया कैसी होगी। मगर अगला सवाल यह आया कि डीएनए कैसे तय करेगा कि किसी प्रोटीन में कौन-कौन-से अमीनो अम्ल जुड़ेंगे और उनका क्रम क्या होगा। चूँकि डीएनए ाृंखला में बाकी चीज़ें (शर्करा और फॉस्फेट) तो एक जैसी दोहराई जाती हैं, सिर्फ क्षार बदलते हैं, इसलिए यह सोचना लाज़मी था कि येन-केन प्रकारेण इन्हीं क्षारों (A, T, C और G) से प्रोटीन में अमीनो अम्लों के क्रम का निर्धारण होगा। कैसे? यह एक तरह से अनुवाद की समस्या है - एक आणविक भाषा (न्यूक्लियोटाइड्स के क्षारों की भाषा) को दूसरी आणविक भाषा (प्रोटीन के अमीनो अम्लों की भाषा) में अनुदित करना। इसलिए इस प्रक्रिया को ट्रांसलेशन कहते हैं। मगर उससे पहले एक और बात पर विचार करना होगा।
यूकेरियोटिक (यानी केन्द्रक युक्त) कोशिकाओं में डीएनए तो केन्द्रक में होता है, मगर प्रोटीन का निर्माण कोशिका द्रव्य में होता है। तो डीएनए पर प्रोटीन निर्माण की सूचना जिस भी भाषा में लिखी है, वह केन्द्रक से बाहर कैसे आती है? क्या डीएनए के सम्बन्धित खण्ड स्वयं बाहर आते हैं या किसी और तरीके से यह सूचना बाहर पहुँचाई जाती है? चूँकि कोशिका द्रव्य में डीएनए नहीं पाया जाता, इसलिए यह स्पष्ट है कि कोई अन्य मध्यस्थ अणु होना चाहिए जो प्रोटीन निर्माण के काम को संचालित करे।
इस सन्दर्भ में सबसे पहली उपयोगी सूचना यह थी कि बहुत तेज़ी से प्रोटीन निर्माण कर रही कोशिकाओं (जैसे पैंक्रियाज़) में बहुत अधिक मात्रा में राइबोन्यूक्लिक एसिड (संक्षेप में आरएनए) पाया जाता है, जबकि अन्य ‘अक्रिय’ कोशिकाओं में इसकी मात्रा बहुत कम होती है। तो यह अन्दाज़ लगाना स्वाभाविक था कि शायद आरएनए ही वह मध्यस्थ अणु है। यह भी देखा गया था कि आरएनए कोशिका द्रव्य में भी पाया जाता है और केन्द्रक में भी। आगे चलकर रेडियोसक्रिय तत्वों के उपयोग से हुए प्रयोगों से पता चला कि आरएनए का निर्माण केन्द्रक में होता है और वहाँ से उसे कोशिका द्रव्य में भेजा जाता है।
डीएनए और आरएनए में तीन प्रमुख अन्तर होते हैं:
1. डीएनए में शर्करा डीऑक्सीराइबोस होती है जबकि आरएनए में राइबोस।
2. जहाँ-जहाँ डीएनए में थायमीन क्षार होता है, वहाँ-वहाँ आरएनए में यूरेसिल (U) होता है।
3. सामान्यत: आरएनए दोहरी नहीं, इकहरी ाृंखला के रूप में पाया जाता है।
इन अन्तरों के बावजूद ज़ाहिर है कि डीएनए के साँचे से आरएनए का अणु आसानी से बन सकता है।
ट्रांसक्रिप्शन की क्रिया
डीएनए के अणु की मदद से आरएनए का अणु बनाने की क्रिया को ट्रांसक्रिप्शन कहते हैं। आज हम जानते हैं कि आरएनए भी एक किस्म का नहीं होता। यह आरएनए जो डीएनए की मदद से आम तौर पर केन्द्रक में बनाया जाता है और कोशिका द्रव्य में भेजा जाता है, इसे सन्देशवाहक आरएनए या मेसेंजर आरएनए (एम-आरएनए) कहते हैं। दो अन्य आरएनए की बात हम तब करेंगे जब उनकी ज़रूरत पड़ेगी। अभी तो ट्रांस्क्रिप्शन को देखते हैं।
किसी भी जैविक क्रिया के समान ट्रांस्क्रिप्शन की क्रिया में भी एंज़ाइम2 की ज़रूरत होती है। ट्रांस्क्रिप्शन की क्रिया के लिए एक एंज़ाइम नहीं बल्कि एंज़ाइम्स का एक संकुल होता है - आरएनए पोलीमरेज़। यह एंज़ाइम डीएनए के किसी विशेष स्थान से जुड़ जाता है। जैसा कि पहले ही कहा जा चुका है डीएनए न्यूक्लियो-टाइड्स का एक क्रम है। यानी डीएनए पर एक विशेष क्रम में चार क्षार लगे होंगे। बस इतना ही करना है कि जो क्षार डीएनए पर लगा हो, उसका पूरक क्षार उसके सामने लाकर रख दिया जाए। यानी जहाँ ॠ है उसके सामने छ (च्र् नहीं) और जहाँ क् है उसके सामने क्र जोड़ा जाए। इस तरह से एक-एक करके न्यूक्लियोटाइड (राइबोस शर्करा, फॉस्फेट व क्षार की इकाइयाँ) जुड़ते जाते हैं और सम्बन्धित खण्ड की पूरक प्रति बन जाती है। जब यह प्रति बनाने का काम पूरा हो जाता है तो आरएनए का अणु अलग हो जाता है। बात तो बस इतनी ही है। मगर इस इतनी-सी बात से कई सवाल उठते हैं।
|
ट्रांस्क्रिप्शन का आरम्भ व अन्त डीएनए पर इस बात का संकेत क्षारों के क्रम के रूप में अंकित होता है कि ट्रांस्क्रिप्शन की क्रिया कहाँ से शु डिग्री होगी और कहाँ समाप्त होगी। ई. कोली बैक्टीरिया का उदाहरण लें, तो प्रमोटर के रूप में पहले TTGCA क्षारों का क्रम होता है और उसके बाद 17 क्षारों का एक और क्रम होता है। इसके बाद TATATT आता है। आरएनए पोलीमरेज़ यहीं जुड़ता है। समाप्ति बिन्दु बहुत रोचक है। जहाँ आरएनए ट्रांसक्रिप्शन रुकना है वहाँ डीएनए पर क्षारों की जो लड़ी होती है वह ऐसी होती है कि यदि उसे दोहरा किया जाए तो वे क्षार परस्पर जोड़ी बना सकते हैं - यानी वह हिस्सा मुड़कर हेयरपिन के समान छल्ला-सा बना लेता है। जहाँ यह लड़ी आई उसके बाद आठ थायमीन क्षार होते हैं। |
सबसे पहला सवाल तो यही उठता है कि आरएनए पोलीमरेज़ को पता कैसे चलता है कि किस खण्ड की नकल बनानी है। वह खण्ड शु डिग्री कहाँ से होता है? यानी कोई ‘जीन’ डीएनए की लम्बी शृंखला पर कहाँ बैठा है?
ट्रांसक्रिप्शन खण्ड की शुरुआत दर्शाने के लिए डीएनए शृंखला पर क्षारों का एक क्रम होता है। इसे प्रमोटर कहते हैं। आरएनए पोलीमरेज़ यहीं जुड़ता है। पोलीमरेज़ के जुड़ने के बाद ही डीएनए की दो परस्पर लिपटी हुई शृंखलाएँ एक-दूसरे से अलग-अलग होती हैं और आरएनए निर्माण के लिए जगह बनती है। इस जुड़ाव बिन्दु से सात क्षारों के बाद वास्तविक प्रारम्भ बिन्दु होता है (क्षारों की शृंखला क्ॠच्र्)। यहीं से न्यूक्लियोटाइड डीएनए पर मौजूद क्षारों के अनुसार एक के बाद एक जुड़ते हैं और आरएनए शृंखला बनती जाती है जब तक कि समाप्ति बिन्दु नहीं आ जाता। बस, यहीं पर ट्रांस्क्रिप्शन की क्रिया रुक जाती है, आरएनए अलग हो जाता है।
यानी अब आपके पास डीएनए का पूरक आरएनए है। यह कोशिका द्रव्य में चला जाता है। वहाँ आगे की क्रिया यानी प्रोटीन का निर्माण राइबोसोम नामक संरचना में होता है। मगर उससे पहले कुछ काम बाकी बचा है।
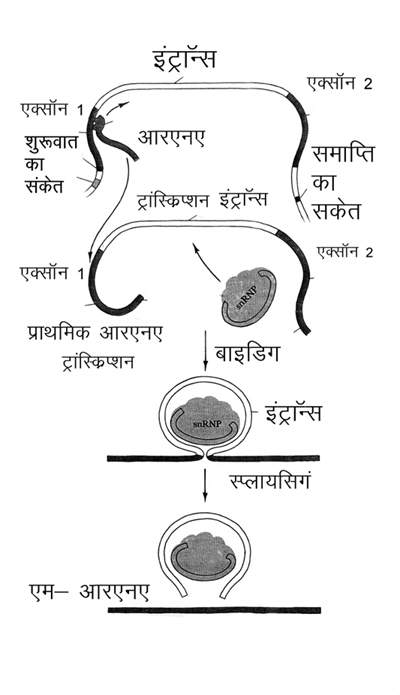 केन्द्रकयुक्त कोशिकाओं में ट्रांस-क्रिप्शन में एक बड़ा अन्तर यह होता है कि यह सन्देश वाहक आरएनए का अन्तिम प्रारूप नहीं है बल्कि प्रारम्भिक ट्रांस्क्रिप्ट है। अभी इसका सम्पादन किया जाएगा, इसके पहले कि अनुवाद (प्रोटीन निर्माण) का काम शु डिग्री हो। एक प्रयोग में देखा गया था कि जो प्रारम्भिक ट्रांस्क्रिप्ट बनी वह तो 6000 न्यूक्लियोटाइड लम्बी थी मगर वास्तव में जिस ट्रांस्क्रिप्ट के आधार पर प्रोटीन का निर्माण हुआ वह मात्र 2000 न्यूक्लियोटाइड लम्बी थी। बाद में किए गए प्रयोगों से पता चला कि यह एक सामान्य प्रक्रिया है कि केन्द्रक में ही प्रारम्भिक एम-आरएनए में से कुछ हिस्से काटकर अलग किए जाते हैं। इन हिस्सों को इन्ट्रॉन्स कहते हैं। जो हिस्से इस काट-छाँट के बाद बचते हैं उन्हें एक्सॉन कहते हैं और इन्हें आपस में सिल दिया जाता है। इस क्रिया को स्प्लायसिंग कहते हैं। एक्सॉन को सिलकर जो शृंखला बनती है वह एम-आरएनए है जिसे केन्द्रक से बाहर भेज दिया जाता है।
केन्द्रकयुक्त कोशिकाओं में ट्रांस-क्रिप्शन में एक बड़ा अन्तर यह होता है कि यह सन्देश वाहक आरएनए का अन्तिम प्रारूप नहीं है बल्कि प्रारम्भिक ट्रांस्क्रिप्ट है। अभी इसका सम्पादन किया जाएगा, इसके पहले कि अनुवाद (प्रोटीन निर्माण) का काम शु डिग्री हो। एक प्रयोग में देखा गया था कि जो प्रारम्भिक ट्रांस्क्रिप्ट बनी वह तो 6000 न्यूक्लियोटाइड लम्बी थी मगर वास्तव में जिस ट्रांस्क्रिप्ट के आधार पर प्रोटीन का निर्माण हुआ वह मात्र 2000 न्यूक्लियोटाइड लम्बी थी। बाद में किए गए प्रयोगों से पता चला कि यह एक सामान्य प्रक्रिया है कि केन्द्रक में ही प्रारम्भिक एम-आरएनए में से कुछ हिस्से काटकर अलग किए जाते हैं। इन हिस्सों को इन्ट्रॉन्स कहते हैं। जो हिस्से इस काट-छाँट के बाद बचते हैं उन्हें एक्सॉन कहते हैं और इन्हें आपस में सिल दिया जाता है। इस क्रिया को स्प्लायसिंग कहते हैं। एक्सॉन को सिलकर जो शृंखला बनती है वह एम-आरएनए है जिसे केन्द्रक से बाहर भेज दिया जाता है।
अब एम-आरएनए कोशिका द्रव्य में पहुँच गया है। यहाँ अनुवाद कार्य होना है। अर्थात् न्यूक्लियोटाइड की भाषा को अमीनो अम्लों की भाषा में तबदील किया जाएगा। मगर पहले यह समझना ज़रूरी है कि न्यूक्लियो-टाइड की भाषा और अमीनो अम्लों की भाषा के शब्दों में पर्यायवाची शब्द कौन-से हैं। यानी इन दो भाषाओं में क्या समरूपता है।
चार क्षारों से 20 अमीनो अम्ल
प्रोटीन दरअसल, अमीनो अम्लों की ाृंखला से बने होते हैं। वैसे तो अमीनो अम्ल कई सारे हैं मगर सजीवों में 20 अमीनो अम्लों का उपयोग प्रोटीन निर्माण में होता है। किसी भी प्रोटीन में अमीनो अम्लों का एक विशेष क्रम होता है। सवाल है कि एम-आरएनए इस क्रम में अमीनो अम्लों को जमाने में कैसे मदद करेगा।
जैसा कि पहले कहा गया था, यह तो अन्दाज़ लग ही गया था कि क्षार ही किसी प्रकार से अमीनो अम्लों के द्योतक होंगे। मगर क्षार हैं चार और अमीनो अम्ल हैं 20। तो एक-एक क्षार एक-एक अमीनो अम्ल का द्योतक तो नहीं हो सकता। यदि हम दो-दो की जोड़ियाँ बनाएँ तो कुल 16 जोड़ियाँ बनेंगी। फिर भी 4 अमीनो अम्ल बच जाएँगे। तो एक बात तो तय थी कि प्रत्येक अमीनो अम्ल के लिए तीन-तीन या उससे ज़्यादा की लड़ियाँ लगेंगी। आज हम जानते हैं कि तीन क्षारों की एक तिकड़ी किसी एक अमीनो अम्ल की द्योतक होती है। द्योतक होती है मतलब यदि क्षारों की वह तिकड़ी एम-आरएनए पर है तो उससे सम्बन्धित अमीनो अम्ल वहाँ जुड़ेगा। इसे एक कोडॉन कहते हैं। कोडॉन तीन क्षारों का होता है यह बात फ्रांसिस क्रिक व उनके साथियों ने अत्यन्त चतुर प्रयोगों से पता की थी (देखें बॉक्स - आरएनए और प्रोटीन की भाषा के शब्द)। कई सारे अन्य चतुराई भरे प्रयोगों से यह भी पता चल गया कि क्षारों के कौन-से क्रम किस अमीनो अम्ल के द्योतक हैं (देखें एक और बॉक्स - समतुल्य शब्द)।
|
आरएनए और प्रोटीन की भाषा के शब्द (कोडॉन) ध्यान देने की बात यह है कि क्षार तो एक के बाद एक जुड़े हुए हैं। उन पर कोई चिन्ह नहीं है कि ये तीन या ये चार एक अमीनो अम्ल के द्योतक हैं। फ्रांसिस क्रिक व उनके साथियों ने तर्क लगाया कि यदि शु डिग्री के एक न्यूक्लियो-टाइड को हटा दिया जाए या एक न्यूक्लियो-टाइड जोड़ दिया जाए, तो मात्र एक कोडॉन नष्ट नहीं होगा बल्कि पूरा कोड ही तहस-नहस हो जाएगा। जैसे यह कोड देखिए: |
तो डीएनए से प्रारम्भिक एम-आरएनए बना, उसमें से इन्ट्रॉन्स की छँटाई करके, एक्सॉन्स की सिलाई करके एम-आरएनए का अन्तिम प्रारूप तैयार हुआ। इसे केन्द्रक से बाहर भेज दिया जाता है, जहाँ यह प्रोटीन संश्लेषण में भूमिका निभाएगा। वैसे ताज़ा जानकारी बताती है कि इस अन्तिम प्रारूप में भी काट-छाँट होती है और यहाँ तक कि प्रोटीन बनने के बाद उसमें भी काट-छाँट की जाती है। मगर उस सबमें न पड़कर देखें कि प्रोटीन बनने की क्रिया यानी ट्रांसलेशन कैसे होता है।
|
समतुल्य शब्द (कोडॉन) क्रिक के काम से पता चल गया कि तीन-तीन क्षारों का क्रम एक-एक अमीनो अम्ल का कोड है। क्षार कुल चार हैं और उनके तीन-तीन के कुल 64 क्रम बनते हैं। यानी क्षार-क्रम ज़्यादा हैं और अमीनो अम्ल कम हैं। मतलब काफी सारे फालतू क्रम होंगे। आज हम जानते हैं कि कौन-से क्षार-क्रम किस अमीनो अम्ल के कोडॉन हैं। यह पता करना भी काफी रोचक था। एक बानगी। |
ट्रांसलेशन और राइबोसोम
ट्रांसलेशन की क्रिया राइबोसोम में सम्पन्न होती है। तो पहले ज़रा राइबोसोम को देख लिया जाए। यूकेरियोटिक (यानी केन्द्रक युक्त) कोशिकाओं में राइबोसोम कोशिका द्रव्य में बिखरे हुए नहीं पाए जाते बल्कि एंडोप्लाज़्मिक जाल पर चिपके होते हैं। राइबोसोम की दो इकाइयाँ होती हैं - एक बड़ी व एक छोटी। सामान्य अवस्था में ये दोनों अलग-अलग रहती हैं। ये दोनों इकाइयाँ तभी आपस में जुड़ती हैं जब एम-आरएनए आकर छोटी इकाई से जुड़ जाता है। अब करना सिर्फ इतना है कि एम-आरएनए के क्षार-क्रम के अनुसार एक-एक अमीनो अम्ल आता जाए और जमता जाए। अन्त में इन सारे अमीनो अम्लों को जोड़कर प्रोटीन का अणु बन जाएगा। सवाल यह है कि विभिन्न अमीनो अम्ल कोशिका द्रव्य में बिखरे पड़े हैं। ये क्योंकर राइबोसोम की ओर भागने लगेंगे? इन्हें राइबोसोम तक लाने की भी व्यवस्था है।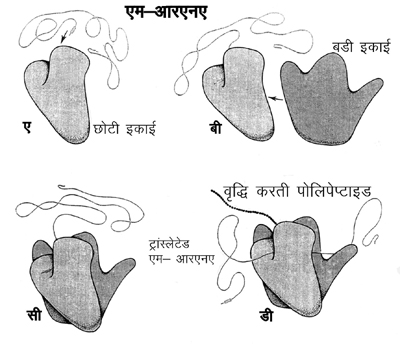 जब एम-आरएनए राइबोसोम से जुड़ जाता है, तो उसके एक-एक कोडॉन (यानी न्यूक्लियोटाइड की तिकड़ी) से एक-एक आरएनए बनाया जाता है। ये छोटे-छोटे आरएनए कोशिका द्रव्य में बिखर जाते हैं और सही अमीनो अम्लों को अपने साथ जोड़कर राइबोसोम तक ढोने का काम करते हैं। इन छोटे-छोटे आरएनए को परिवहन आरएनए (ट्रांसफर आरएनए या टी-आरएनए) कहते हैं।
जब एम-आरएनए राइबोसोम से जुड़ जाता है, तो उसके एक-एक कोडॉन (यानी न्यूक्लियोटाइड की तिकड़ी) से एक-एक आरएनए बनाया जाता है। ये छोटे-छोटे आरएनए कोशिका द्रव्य में बिखर जाते हैं और सही अमीनो अम्लों को अपने साथ जोड़कर राइबोसोम तक ढोने का काम करते हैं। इन छोटे-छोटे आरएनए को परिवहन आरएनए (ट्रांसफर आरएनए या टी-आरएनए) कहते हैं।
प्रोकेरियोटिक कोशिकाओं में केन्द्रक तो होता नहीं, इसलिए उनका डीएनए कोशिका द्रव्य में ही होता है। इनमें एक तरफ ट्रांस्क्रिप्शन (यानी डीएनए से एम-आरएनए बनाने) की क्रिया चल रही होती है, और उसी समय साथ-साथ ट्रांसलेशन भी शुरू हो जाता है। यूकेरियोटिक कोशिकाओं में ट्रांस्क्रिप्शन पूरा होने के बाद ही एम-आरएनए केन्द्रक से बाहर आता है।
तो प्रोटीन बन गया। मगर अभी यह प्रोटीन किसी काम का नहीं है। यह तो सिर्फ उसका रासायनिक ढाँचा है। इसमें अभी कई परिष्कार होना बाकी हैं। वह काम कोशिका के अन्य उपांग करेंगे।
प्रोटीन निर्माण की यह प्रारूपिक कहानी है। लेकिन इसमें कई बारीकियाँ हैं जिनकी बात हम फिर कभी करेंगे। जैसे हमने देखा कि डीएनए से आरएनए बनना, आरएनए से प्रोटीन बनना वगैरह क्रियाओं के लिए कुछ एंज़ाइम ज़रूरी होते हैं। ये एंज़ाइम प्रोटीन ही होते हैं और ये भी तो उसी डीएनए से बनेंगे। तो इन्हें बनाने का काम कैसे होता है? हमने यह भी देखा कि किसी जीव की लगभग सारी कोशिकाओं में पूरा-का-पूरा डीएनए मौजूद होता है। इसका मतलब है कि हरेक कोशिका के पास समस्त प्रोटीन बनाने की सूचना उपलब्ध है। मगर हरेक कोशिका सारे प्रोटीन बनाती नहीं। तो कैसे तय होता है कि पूरे डीएनए में से किस सूचना का उपयोग होगा? इस अन्तिम । के साथ बात रोकता हूँ।
सुशील जोशी: एकलव्य द्वारा संचालित स्रोत फीचर सेवा से जुड़े हैं। विज्ञान शिक्षण व लेखन में गहरी रुचि।